这篇文章来自于segmentfault, 很具有代表性
如果有关心SF发展同学肯定通过不少渠道了解到我们正在对它进行全站的重构,现在重构已经进入了尾声,而且内部测试也已经经过了一个阶段,所以不出意外的话,这个新版本过不了几天就会出现在大家面前了。
那么这次重构在系统上有什么进步呢?
系统架构的大大加强
在过去的一年,SF因为系统的制约发生了不少起宕机事故,有的时候甚至长达数小时之久,大大影响了用户的体验,因此在这次重构之初,我们就下决心从系统层面开始解决这一问题。
截止到2014年9月15日,大家看到的虽然还是老版本的界面,但是实际上背后已经迁移到新的系统架构上了,并且在这段时间内没有发生任何访问故障或者宕机事故,新的系统架构威力初显。
那么SF以前的系统架构是什么样子呢?我的回答是没有什么架构,因为所有的服务都放在一台服务器上,这个答案可能让很多用户大跌眼镜。
是的,受制于创办之初的资金限制,我们的网站只有一台服务器。在后期访问量逐渐增大的情况下,这台服务器状况不断,如果有一天它突然挂掉,那恢复它可就费事了。
云主机助力
对于SF这样的初创企业,自己建立数据中心显然是性价比极低的选择,但是系统架构的限制又逼迫我们不得不做出改变。幸好现在已经进入了云时代,大量的基础设施问题可以交给更专业的服务商解决。经过一系列权衡,我们最终选择了青云作为我们的云主机提供商。
- 4 * web服务器(其中一台备用)
- 1 * db服务器(得力于ssd和缓存的使用,目前一台db是可以满足需求的)
- 1 * 搜索服务器
- 1 * 缓存服务器
- 1 * 后台服务服务器
一般工作的就是这8台服务器
更加颗粒化的系统划分
这一点在web服务器系统的设计上尤为突出,它是所有服务器中压力最大的,因此机器数量也是最多。但是每台服务器的配置却是最小的 单核1G 的实例。
这种颗粒化的划分,有以下几个好处
- 节约成本,如果我们一次性配置一台多核大内存的服务器,成本是很高的,而且大部分情况下性能是有浪费的。
- 增加可靠性,一台机器挂掉的可能性远大于多台机器同时挂掉
- 方便水平扩展,你可能已经注意到我设计了一台备用服务器,它平时就是挂在负载均衡节点上的,只是不需要开机(如果不开机是不会计费的),当遇到突然增加的访问量时,我们可以实时启动这台服务器,从而瞬间减轻其它节点的压力。而访问量降低后,我们又可以关掉它,降低使用成本。
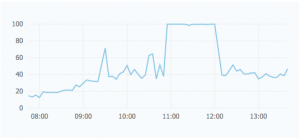
比如上面这张图就是一次典型的流量冲击处理,在11点左右网站的访问量陡增,前端web的负载全部到顶,根据它的增长曲线,我们判断这是一次恶意抓取。需要我们在程序上做防护的同时在这期间不影响用户访问,因此我们将第四台备用服务器的配置临时调整到 4核2G,并在12点左右上线,系统负载马上恢复到了正常水平
改变代码上线模式
通常的上线流程就是直接把可发布的代码通过rsync之类的同步到线上机器。
在新版的SF中我们根据PHP的特点改变了这一模式,我们将代码打包成phar发布到服务器,每上线一次就重新打一个包,并将其文件名命名为版本号,比如14.9.5.195755.1718937340.phar。打包发布有如下好处
- 方便管理,只有一个文件,而且传输比以前的同步模式更加快速,并且可以避免当某些文件没有同步完用户就来访问的错误
- 可以回滚,回滚非常方便,在配置文件里将需要加载的包版本号改成你需要回滚的版本即可,可以快速完成灾难恢复
更加好地依赖云服务
除了我们的云主机,我们还使用了如下云服务
- Amazon SES,群发邮件价格便宜量又足
- Mailgun,目前我们的主力邮件发送服务,大家的通知提醒服务都是通过它
- SendCloud,备份邮件发送服务,主要用来发一些mailgun无法收到的邮件,比如QQ Mail等等
- 又拍云,所有的静态文件,包括用户头像和上传图片的存储
- NewRelic,程序性能监测
Todo
虽然我们已经达成了一个milestone,但是后面要做的事情依然很多,并且我们的后端服务能力会逐渐加强。我们后续的工作会围绕数据流的处理展开,我们也会使用更多的技术来完善我们的服务,Node.js,Go-lang,Scala,都是我们的选项。也欢迎在这方面有经验的工程师加入我们