- Set up static IP for management console using DUCI (Direct Console User Interface)
- Enable Secure Shell Access (on demand only)
- Configure ESXi firewall, Networking – > Firewall Rules
- Configure NTP, In Navigator, Manage -> System -> Time & date
- log management
VMware vSphere licenses
vSphere (esxi 6.7) 主要有4个版本:
VMware vSphere Standard, VMware vSphere Enterprise Plus, VMware vSphere with operations management, VMware vSphere Platinum
Platinum 和 Enterprise Plus 基本都一样,除了AppDefense
除了面向大企业的版本,还有专门面向small business 的版本
VMware vSpher Essential Kit 和 VMware vSphere Essentials Plus Kit
VMware vSphere 和 vCenter 下载地址及序列号
如果你在vmware.com 网站的60天evaluation 账号过期了无法下载最新版的esxi 和 vcenter 的话,可以使用下面的下载地址去下载最新版的:
https://technet24.ir/vmware-vcenter-server-6-7-13940
下载完毕以后可以去vmware 官网的摘要去进行比较
https://my.vmware.com/cn/group/vmware/details?downloadGroup=VC67U2A&productId=742#errorCheckDiv
授权的序列号可以参见下方的链接:
http://www.i5i6.net/post/190.html
vCenter Server Licensing Option
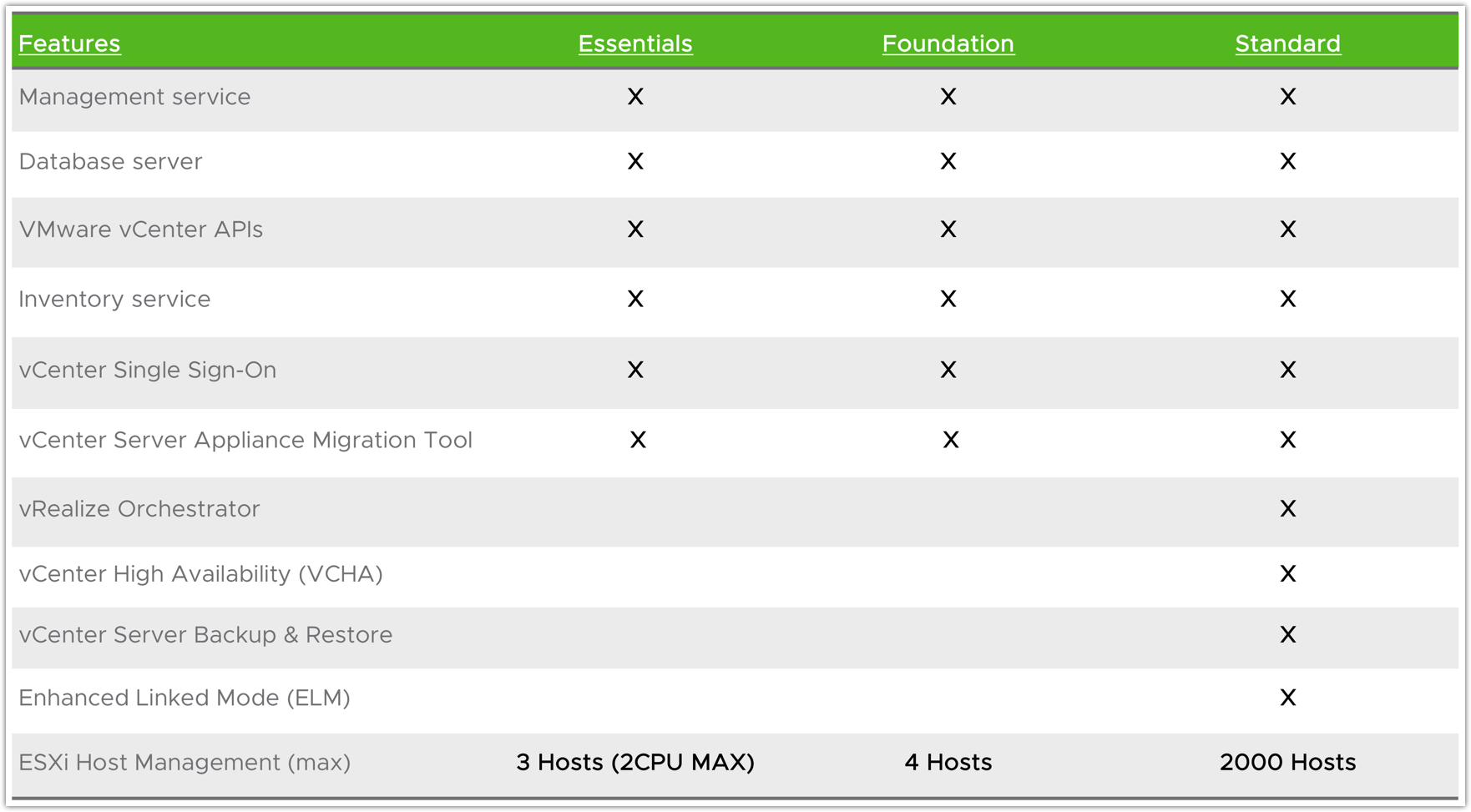
vCenter Server 主要有三种不同的license: Standrad, Foundation 和 Essentials
其中Standard 和 Foundation 的授权是单独售卖的, Essential 的授权是保罗在vSphere Essentials Kit 中的,可以参考下图的比较:
VCSA 的安装部署
vCenter 可以安装在windows 后者linux VM上,但是随着vSphere 6.5 出来以后,vCenter 开始只推荐在Linux VM 上安装,叫做vCenter Server Applicance,简称vCSA
vCSA 的ISO 很大。有3G 多,因此对于需要部署国外服务器的国内用户来说,可以在远程的windows 上进行安装vCSA,需要注意的是vCSA 的安装方式比较有意思,需要是Linux 的需要机,但是需要windows 的机器来远程连接到vSphere,通过api 来设置Linux VM
在windows 10 和 Windows Server 2016 上, 需要使用虚拟光驱来打开ISO 文件, 我们可以使用Virtual CloneDrive 来读取ISO文件
安装过程需要两步, Deploying the vCenter Server Appliance 和 Configuring the vCenter Server Appliance,全程 GUI简单易懂,所以就不过多介绍,可以参见这篇文章:
https://community.hetzner.com/tutorials/install-and-configure-vmware-vcenter
需要注意的一点是: 如果VCSA 部署在public IP上,没有什么问题,直接按照文章来做就可以了。但是如果VCSA 部署在private IP上,那么ESXi Host 的vmkernel NIC 需要和 VCSA 在同一网段,这样他们能够互相communication。
还有一点就在选择VCSA 所在的datastore 的时候,可以选择“Thin Provision”
Thin 和 Thick 是相对的, Thin 只会占用实际使用的disk 空间, Thick 则是选择使用多大,就占用多大。 例如一个300GB 的virtual disk上面有70GB 的数据,对于Thin mode 来说,就只占用70GB,对于thick mode来说,就会占用300GB
最后很重要的一点是,如果你使用的是hetzner,ovh,online.net 的话,当系统完成第一阶段的deployment 的话不会自动进入第二阶段,这是因为这几家所有的网卡的mac address 都必须先注册完成以后才能开始收发流量.
因此当第一阶段完成后,需要进入vSphere Host Client 更改这个VM 的 mac address 才能继续完成第二阶段的部署
vSphere 和 vCenter 的 6.5, 6.7, 以及7.0的key
VMware vSphere ESXi 7.0 Enterprise Plus(据说是rc版合作伙伴测试密钥,正式版可用. 现在更先进了,出了VMware 的keygen,直接google就能找到)
JJ2WR-25L9P-H71A8-6J20P-C0K3F HN2X0-0DH5M-M78Q1-780HH-CN214 JH09A-2YL84-M7EC8-FL0K2-3N2J2
VMware vCenter 7.0 Standard
104HH-D4343-07879-MV08K-2D2H2 410NA-DW28H-H74K1-ZK882-948L4 406DK-FWHEH-075K8-XAC06-0JH08
VMware vSan 7.0 Enterprise Plus
HN0D8-AAJ1Q-07D00-6U924-CX224 50008-221DH-M7E99-A9CKM-A1030 HN0NH-62051-H75E9-P38RM-0H870
VMware vSphere 7 Enterprise Plus with Add-on for Kubernetes
J1608-4GJEQ-071L8-9VA0H-2MUK6 M10DH-8YL47-474L1-DV3U0-8H054 MM4MR-2G005-H7039-JVCAP-2RAL8
以下是6.5, 6.7的key
vCenter: 0A0FF-403EN-RZ848-ZH3QH-2A73P vSphere: JV425-4h100-vzhh8-q23np-3a9pp
虽然说是适用于vSphere 6.5, 但是6.7 仍然试用
vSphere 6.7: MZ48M-DNK56-ZZJD0-RTCE2-9321X
- 给vCenter 分配license:
在vCenter de vSphere Client 上,点击Menu -> Administrator -> Licensing -> Licenses, 单机 “+” 添加一个新的license,然后再点击Assets,在host上面右击,点击”Assign License”就可以了
2. 给vSphere 分配license:
点击 Manage -> Licensing -> Assign License, 添加新的license
VMkernel in ESXi
从vmware 官方文档看来的定义:
The VMkernel is a high-performance operating system that runs directly on the ESXi host. The VMkernel manages most of the physical resources on the hardware, including memory, physical processors, storage, and networking controllers.
因此VMkernel 可以简单的认为是一个OS
VMWARE ESXI 6.7 基础内容
Xen 已经被越来越多的主流厂商抛弃了,因此我也开始全面拥抱esxi 和 kvm,本篇文章主要介绍esxi 使用方面的一些问题, 目前esi 的最新版是 esxi 6.7 u3(update 3)
关于esxi 6.7 的基本安装和配置,可以参见这篇文章,写的是非常的详细
https://www.experts-exchange.com/articles/33122/HOW-TO-Install-and-Configure-VMware-vSphere-Hypervisor-6-7-ESXi-6-7.html
连接到VMware vSphere Hypervisor 6.7:
其实自从esxi 6.5 开始,就可以使用任何浏览器使用Vmware Host Client来说管理, VMware Host Client 是基于HTML5的
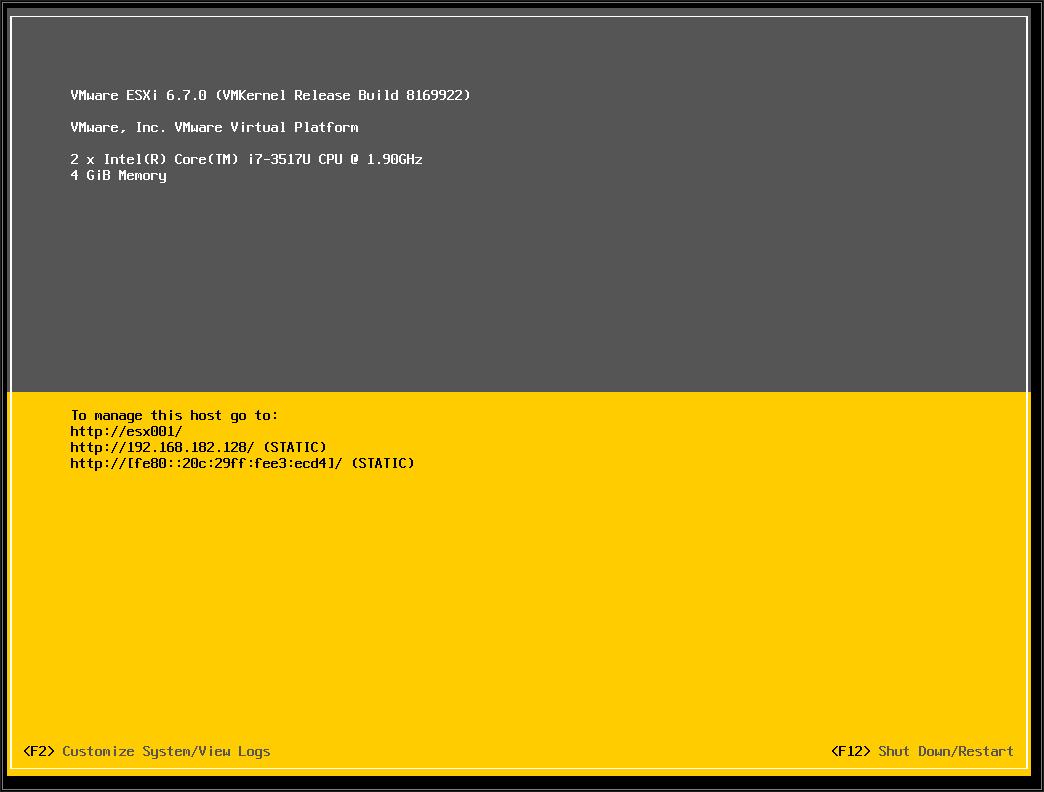
当ESXi 6.7 完全启动以后,上面的画面就会出现,这个叫做Direct Console User Interface (DCUI)
在ESXi 6.5 以前,主要使用基于C#的VMware vSphere Client 来管理,但是从6.5开始, VMware 抛弃了vSphere Client,主要是用基于HTML5的 VMware Host Client 6.7,一个浏览器就可以满足我们的需求
你可以直接访问屏幕上的IP来直接访问Host Client,但是我们更建议使用FQDN来访问Host Client(一定要做好FQDN的A记录)
通过浏览器连接上Host Client 以后,屏幕上就会出现以下画面
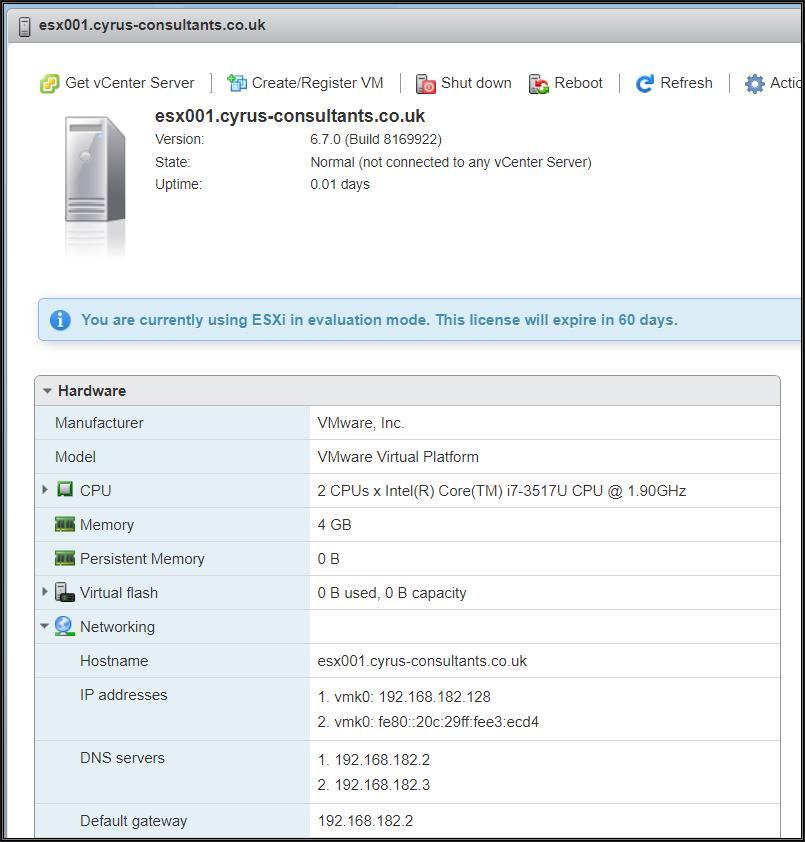
我们注意到ESXi host 没有persistent storage, 如果我们要存储virtual machines(Guests or VMs), VM必须被存储在ESXi host 的datastore 上,类似于windows 的NTFS文件系统, VMware vSphere Hypervisor ESXi 的文件系统叫做VMFS(Virtual Machine File System), VMFS有三个版本,VMFS-3 对应vSphere 3.x 和4.x, VMFS-5 对应于vSphere 5.x 和6.0,VMFS-6 对应于vSphere 6.5和6.7
如果系统没有任何datastore,我们需要点击菜单上的Storage -> New datastore 来创建一个,VMware 的程序做的非常好,简单明了就不多说了. 需要注意的是,只有没有被分区的磁盘或者已经分过区的LVM 或者LUN 才可以被创建成VMFS.
一个tip, 最好创建比较小的disks 或者LUN,因为扩展他们很容易,但是shrink缩小disks 或者LUN 确比较难
上传VM系统的ISO到datastore:
如果本地网速够快,可以使用winscp 或者Veeam Free backup版本: https://www.veeam.com/virtual-machine-backup-solution-free.html
为了方便我们今后做管理,可以在datastore上新建一个文件夹,通过Host Client 这个很简单就可以完成,就不多说了,比如说在datastore1 下面建立一个文件夹 isos
同时单击一下datastore1 的名字,就可以看到他的属性,属性里面包含着这个datastore1 的位置,如下图所示:
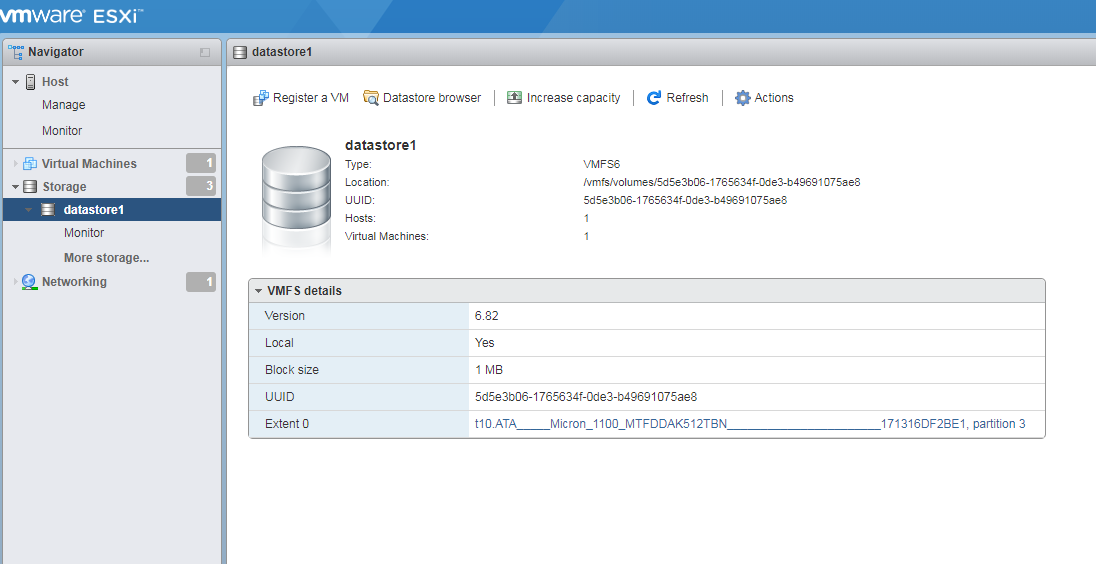
可以看到datastore1 位于/vmfs/volumes/XXXXXXXX
检查文件md5,就需要Esxi 打开SSH access,登录上去用传统的shell commands 来检查
打开SSH access 的步骤:
1) 点击左边菜单中的Host
2)单击屏幕右上方的Actions,在下拉列表中, enable secure shell 和 enable console shell
XenServer 网络配置
从Xenserver 5开始用,到现在都是Xenserver 7.6了,速度真是快。
相应时代的变迁,我也需要从XEN 转移到KVM了,在此记录一下XenServer 的网络配置
Xenserver 默认的network stack 就是vswitch,可以使用如下命令查看network stack
xe host-list params=software-version
在output 中, 查看network_backend, 一般有两个结果, openvswitch 或者 bridge, 默认是openvswitch
bridge 是Linux network stack,如果我们想改回linux network stack, 可以使用如下命令:
xe-switch-network-backend bridge
PIF represents a physical NIC
VIF represents a virtual NIC on a VM
network is a virtual Ethernet switch on a xenserver host
discuz 使用自定义的css
默认default模板都会有module.css 、common.css 2个全局样式表,如果是使用discuz默认default模板,并且只是想修改默认模板中的一些css,那么直接加载其扩展CSS文件中重写就行了!
扩展css文件命名格式:
extend_module.css
extend_common.css
路径为/template/default/common
需要注意的是, extend_common.css 可以直接添加自己想要的css
但是extend_module.css需要 注意他的语法,可以直接参见module.css